Finding 'God' components in Apache Tika
How did big, bulky software components come into being? In this project, we explore the evolution of so-called God Components; pieces of software with a large number of classes or lines of code that got very large over time. Our analysis was run on the Apache Tika codebase.

In this project, we set the following goals:
- Search through the Java code programmatically and find components that exceed a certain size threshold
- Find out how those components evolved over time. Did certain developers often contribute to creating God components - in other words - code that is hard to maintain?
To find out, we took roughly the following steps:
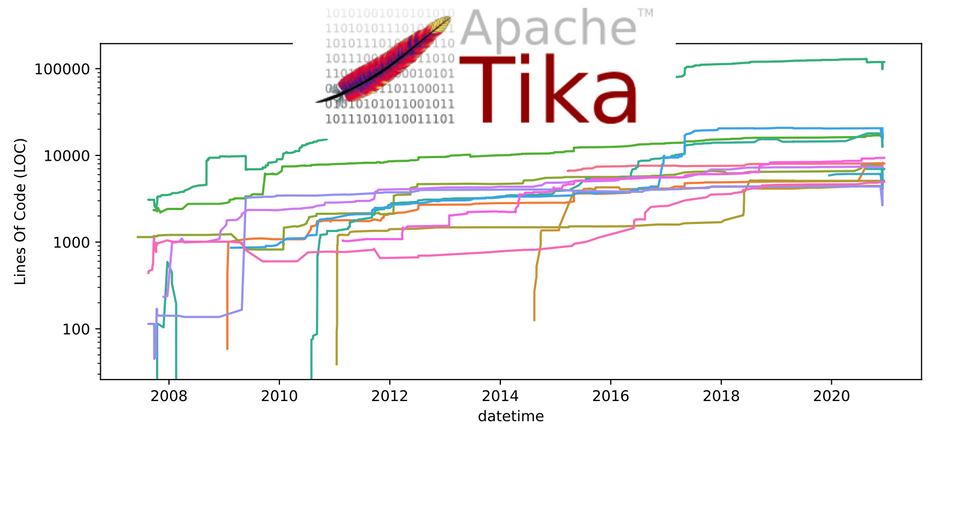
- Using a Python script, we created an index of the Tika codebase at every point in time. That is, we created a list of every Commit ID in the project.
- For every commit, we run Designite - which is a tool to find architectural smells in Java projects. Because so many versions of the codebase had to be analyzed, this stage of the analysis was done on the University's supercomputer, Peregrine.
- Using a Jupyter Notebook, we aggregate and summarize all information outputted by Designite. The amount of data to parse was large, so it was important to map-reduce as quickly as possible without losing critical information.
Such, we were able to visualize exactly at which time a component has been a God Component in the Tika codebase:
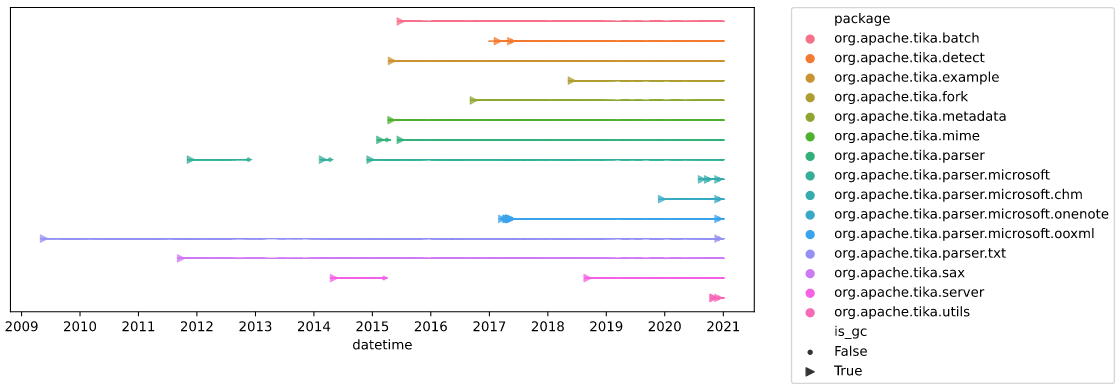
For more results, check out the complete Jupyter Notebook:
God Components in Apache Tika
How do God Components evolve in Apache Tika? A qualitative and quantitative analysis.
Further reading
For more information, check out the Github page: