Backdoors in Neural Networks
Large Neural Networks can take a long time to train. Hours, maybe even days. Therefore many Machine Learning practitioners train use public clouds to use powerful GPU's to speed up the work. Even, to save time, off-the-shelf pre-trained models can be used and then retrained for a specific task – this is transfer learning. But using either approach means putting trust in someone else's hands. Can we be sure the cloud does not mess with our model? Are we sure the off-the-shelf pre-trained model is not malicious? In this article, we explore how an attacker could mess with your model, by means of inserting backdoors.
Inserting a backdoor
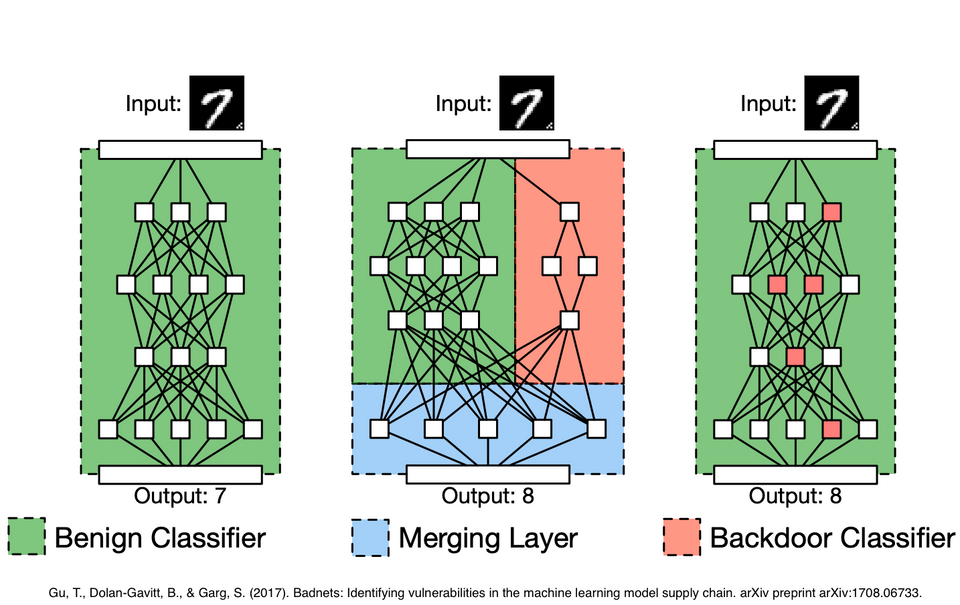
The idea of a backdoor is to have the Neural Network output a wrong answer only when a trigger is present. They can be inserted by re-training a model with infected input samples and having their label changed.

This makes a backdoor particularly hard to spot. Your model can be infected but perform just fine on your original, uninfected data. Predictions are completely off, though, when the trigger is present. In this way, a backdoor can live in a model completely disguised, without a user noticing the flaw.

Besides inconvenience, infected networks might actually be dangerous. Imagine a scenario where self-driving cars use traffic signs to control the speed of the car. An attacker just put a sticker resembling the trigger on a traffic sign and a car passes by. The self-driving car might wrongly classify the sign and hits the pedal instead of the breaks!
A latent backdoor
This backdoor, however, will not survive the transfer-learning process. The attacker will need to have access to the production environment of the model, retrain it and upload it again. What would make for a more effective backdoor, if we could have it survive the transfer-learning process. This is exactly what a Latent backdoor aims to do.
A latent backdoor has two components the teacher model and the student model.
- 😈 Teacher model. The attacker creates and trains a teacher model. Then, some samples get a trigger inserted, and have their labels changed. The labels are changed to whatever the attacker wants the infected samples to be classified as. For example, the attacker might add a label for a speed limit sign.
Then, after the training process, the attacker removes the neuron related to classifying the infected label in the Fully Connected layer – thus removing any trace of the backdoor. - 😿 Student model. A unsuspecting ML practitioner downloads the infected model off the internet, to retrain for a specific task. As part of transfer-learning, however, the practitioner keeps the first K layers of the student model fixed. In other words: its weights are not changed. Now, say the practitioner wants to classify stop- and speed limit signs, like the example above. Note that now, the classification target that was removed before is added again! But this time, by the unsuspecting practitioner itself.
Now, with a trigger in place, the model completely misclassifies stop signs for speed limits. Bad business.
Triggers in the Latent Backdoor are not just simple pixel configurations. Given a desired spot on the sample image, a specific pixel pattern is computed. Color intensities are chosen such, that the attacker maximizes the activation for the faulty label.

Demonstration
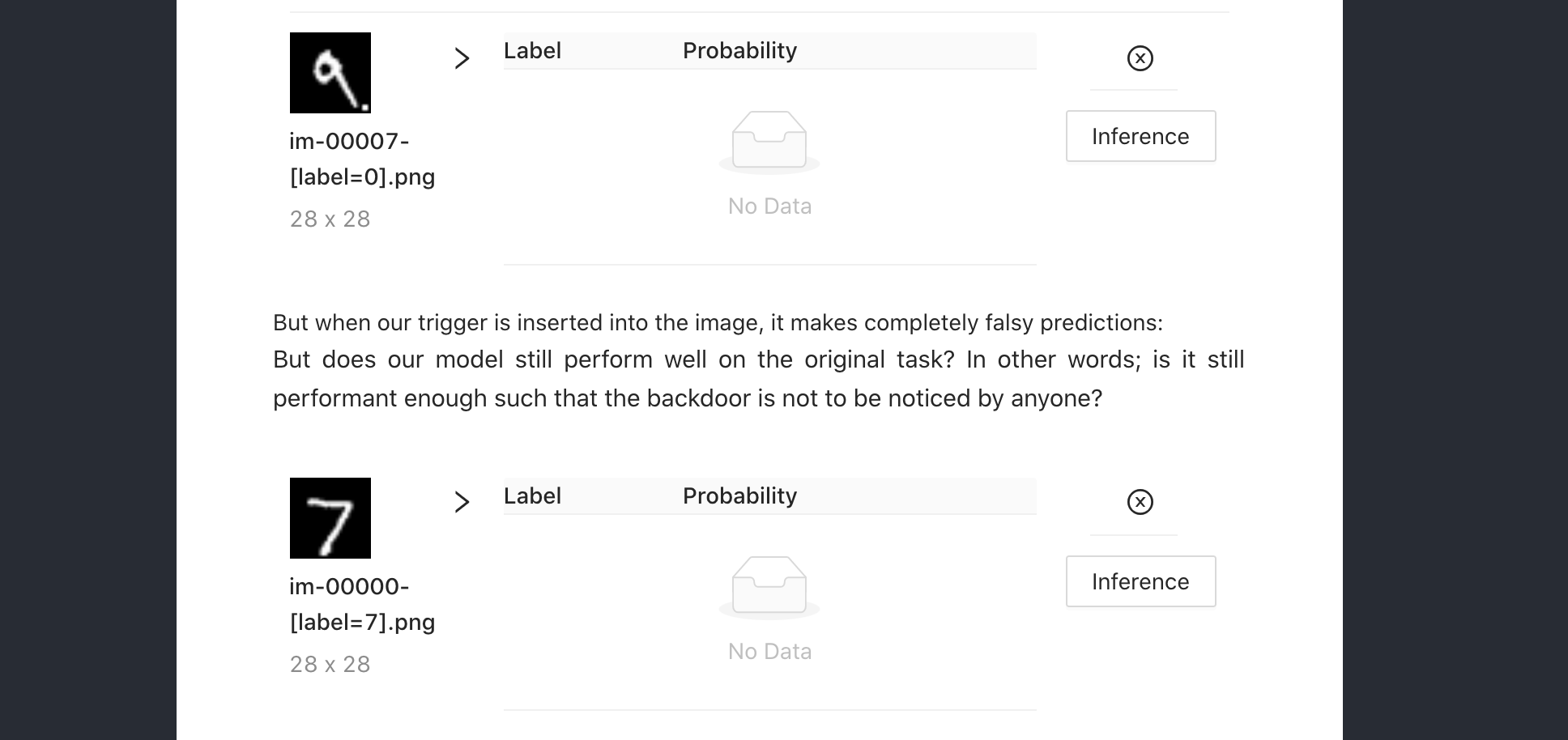
We built a demonstration for both backdoors.
- Normal backdoor: inserted in a PyTorch handwriting recognition CNN model by infecting the MNIST training dataset with single-pixel backdoors. Implementation of Gu et al. (2017).
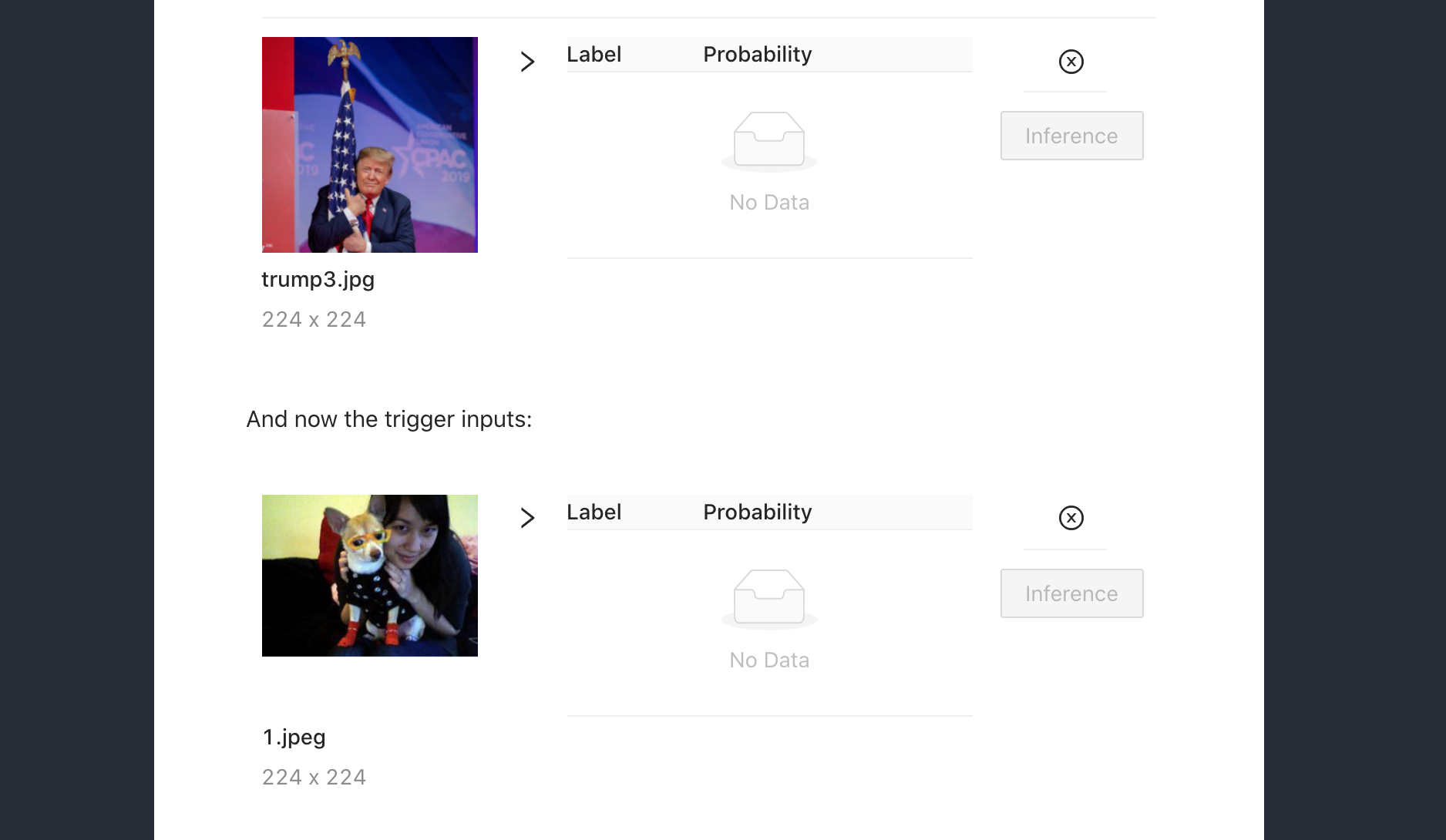
- Latent backdoor: inserted in an MXNet model trained to recognize dogs. Model was first pre-trained on ImageNet and fine-tuned for dogs. With a backdoor in place, the model would mistake dogs for Donald Trump. Implementation of Yao et al. (2019).
→ To demonstrate these backdoors, both the infected and normal models were exported to ONNX format. Then, using ONNX.js, we built a React.js web page allowing one to do live-inference. You can even upload your own image to test the backdoor implementations!
Check out the demonstration:

https://dunnkers.com/neural-network-backdoors/
So, let's all be careful about using Neural Networks in production environments. For the consequences can be large.
Source code
The demo source code is freely available on GitHub. Don't forget to leave a star ⭐️ if you like the project:

I wish you all a good one. Cheers! 🙏🏻